Drieduizend gezichten voor diversere software
Onderzoekers van Facebook hebben een dataset uitgebracht met video’s van mensen van verschillende huidskleuren, leeftijden, geslachten en manieren van belichting. Deze diverse dataset moet bijdragen aan de ontwikkeling van algoritmen die minder last van vooroordelen hebben.
Software voor gezichtsherkenning wordt steeds vaker gebruikt. Maak met je mobiele telefoon een foto van een groep mensen en de software op je smartphone zet snel een vierkantje om de gezichten. In winkels kan een camerasysteem de gezichtsuitdrukkingen van winkelend publiek vastleggen. Er zijn zelfs bewakingscamera’s op de markt met automatische gezichtsherkenning.
Witte gezichten
Die systemen kennen echter grote beperkingen. Vaak zijn ze getraind met datasets die weinig divers zijn. De makers van de gezichtsherkenning-software gebruiken vaak datasets — grote reeksen foto’s van mensen — met voornamelijk witte gezichten. Hierdoor kan het uiteindelijke AI-systeem minder goed mensen met een donkerder huidskleur herkennen.
Precies hetzelfde geldt voor leeftijd: als een bedrijf software ontwikkelt die de leeftijd van een persoon moet inschatten, dan moet het systeem wel zijn getraind met foto’s van mensen van uiteenlopende leeftijden.
Probleem is dat de meeste datasets die worden gebruikt, niet divers genoeg zijn. Daar wil de onderzoeksafdeling van Facebook nu verandering in brengen met het uitbrengen van de dataset Casual Conversations.
45.186 video's
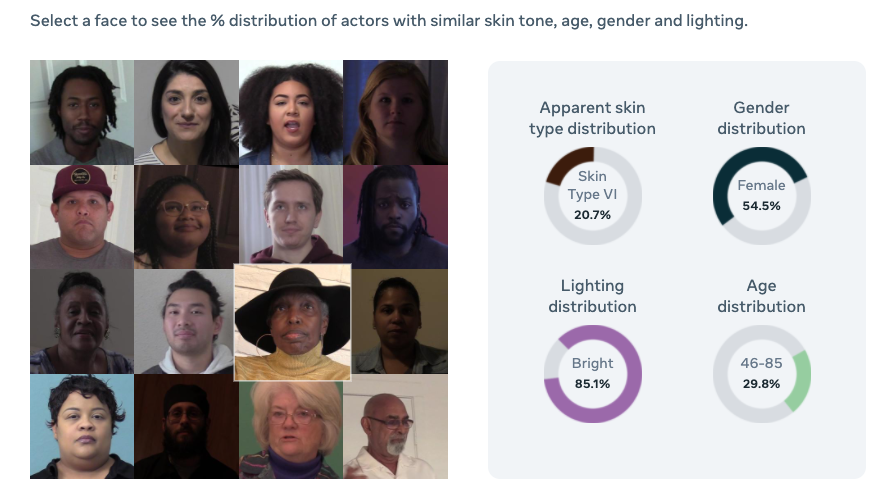
Dit is een verzameling korte video’s van 3.011 mensen die het bedrijf heeft ingehuurd en die op camera eenvoudige vragen beantwoorden. De mensen die zijn gefilmd bestrijken verschillende leeftijden, huidskleuren, geslachten (man, vrouw en ‘anders’) en — ook niet onbelangrijk — kwaliteiten van belichting. Het moet een enorme klus zijn geweest, want de dataset bestaat uit 45.186 video’s, goed voor tien terabyte aan data.
Tekortkomingen
Programmeurs die werken aan zogeheten ‘slimme’ apparaten, die gezichten volgen of herkennen, kunnen hun software in de testfase voeden met deze dataset. Dan merken ze direct als de software voor bepaalde groepen tekortschiet.
‘Uit testen met onze dataset blijkt bijvoorbeeld dat de software niet goed het gezicht herkent van een persoon van een bepaalde leeftijd, kleur of geslacht, bij weinig licht. Dan zou ik, als ontwikkelaar, weten dat mijn algoritme tekortschiet bij een specifieke subgroep’, legt onderzoeksleider Cristian Canton van Facebook AI uit in een nieuwsbericht van IEEE Spectrum.
Dat betekent werk aan de winkel voor de programmeurs, maar het probleem kan dan wel worden aangepakt vóórdat het product in de winkel komt te liggen.
Eerste stap
De nieuwe dataset is pas een eerste stap, realiseren de onderzoekers bij Facebook zich. Hoewel de groep mensen in de video’s diverser is dan in de datasets die doorgaans worden gebruikt, kan het waarschijnlijk nog beter.
Canton, in IEEE Spectrum: ‘Wij hebben gezorgd voor voldoende afwisseling in leeftijd, geslacht, huidskleur en lichtomstandigheden, maar feit is dat alle mensen in onze video’s in de Verenigde Staten wonen. Als we in andere landen zouden gaan opnemen, kwam misschien wel aan het licht dat we een nieuwe vorm van diversiteit moeten toevoegen.’
Accenten
Een heel andere vorm van informatie, die niets met gezichtsherkenning te maken heeft, is audio. De uitspraak van de proefpersonen is nu niet geanalyseerd, maar de onderzoekers vermoeden dat hierin ook nog onbenutte mogelijkheden schuil gaan. Het zijn weliswaar allemaal mensen die in de VS wonen en Engels spreken, maar elk gebied heeft zo zijn eigen accenten. Canton: ‘Wij denken dat de uitspraak in dit verband interessante resultaten zal opleveren.’
Beeldmateriaal Facebook

Meer artikelen