
Video met ingesproken speech lijkt levensecht
Neem een uitgesproken geluidsfragment, plak dat in een video, en het lijkt net een echte toespraak. Met speeches van oud-president Barack Obama wisten onderzoekers van de University of Washington deze nepperij levensecht te maken.
Fake news wordt steeds moeilijker te herkennen. Zeker nu het, met deze techniek, mogelijk wordt om een uitgesproken tekst zo in video-opnames te plakken, dat het net lijkt of de persoon die voor een camera heeft uitgesproken. De woorden zijn dan wel niet nep, want dat is een bestaande opname, maar de presentatie en de context op video zijn dat wel.
Onderzoekers van de Washington University is het gelukt om video’s zo te manipuleren dat ze er gesproken tekst in kunnen plakken, met een levensecht resultaat. Als testobject kozen ze oud-president Barack Obama. Van hem is namelijk veel video beschikbaar, die opnames hebben een continue kwaliteit in hoge resolutie, en meestal is het gezicht in het midden van het beeld te zien. Stuk voor stuk gunstige factoren voor het plakken van audio in de video.
Technisch is het een hele uitdaging om een geluidssignaal te laten passen bij een in 3D bewegend beeld. Dat te meer omdat de bewegingen van het gelaat rond de mond uiterst subtiel zijn. Er is maar weinig voor nodig of gemanipuleerde mondbewegingen zien er onecht uit.
Voor het vertalen van het audiosignaal naar mondbeweging gebruikten de onderzoekers een zelflerend algoritme dat werd getraind met miljoenen videofragmenten. In totaal had het programma 17 uur Obama-video aan trainingsmateriaal.
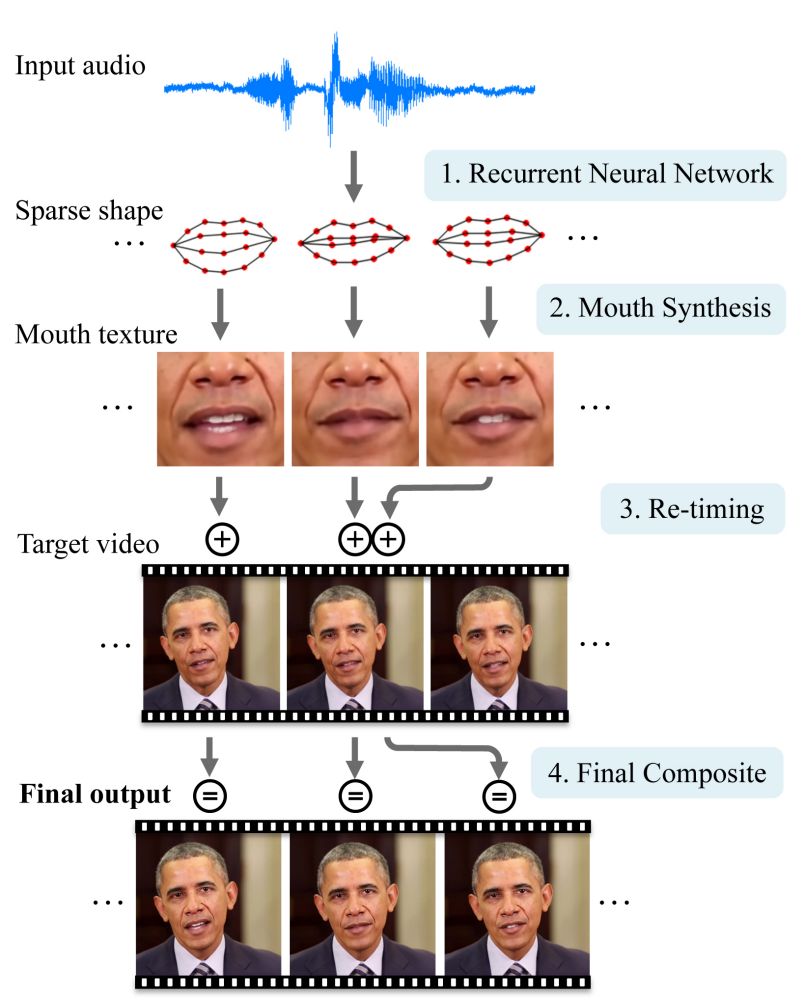
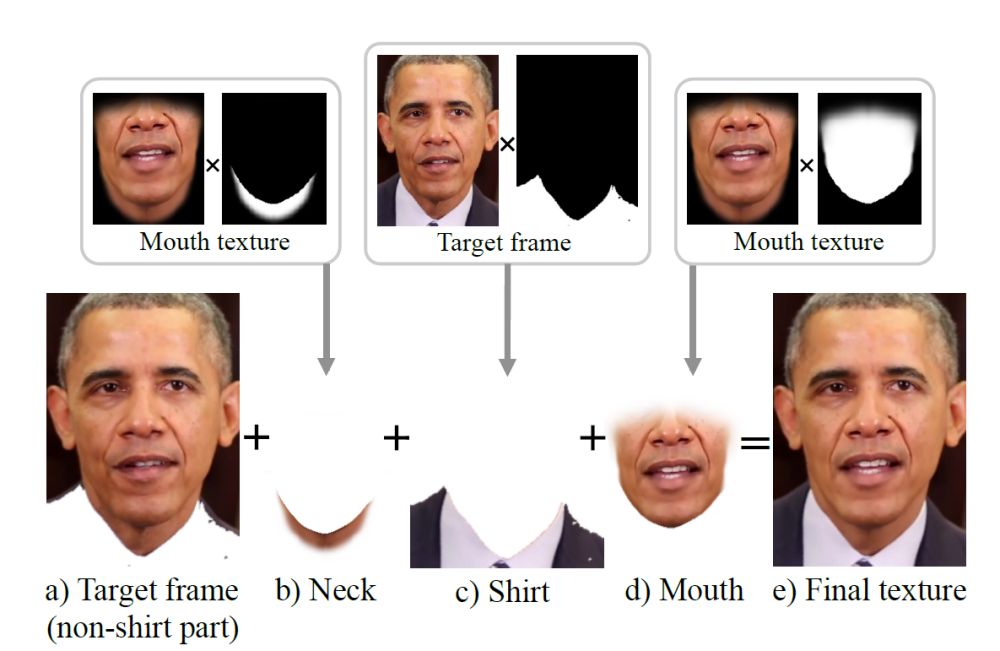
Het omzetten van gesproken tekst naar video gaat dan als volgt: het op Obama getrainde algoritme zet de gesproken tekst voor elk videobeeld afzonderlijk om in een bepaalde stand van de mond. Vervolgens wordt die vorm van de mond gebruikt om het gebied rondom de mond in de video passend te maken, inclusief textuur en lichtval. Dat geheel wordt dan in bestaand videobeeld geplakt, waarbij de hoofdbewegingen zo worden gekozen dat die er natuurlijk uit zien en past bij de gesproken tekst. Tegelijkertijd wordt de kaaklijn passend gemaakt.
Dit gehele proces vergt flink wat rekentijd. Voor 66 seconden spraak had een snelle computer met een 24 core CPU 45 minuten nodig. Uiteindelijk werd de methode getest op een van de wekelijkse gesprekken van Obama met de pers, en twee interviews.
Lastige tongval
Niet alles gaat perfect. Zo heeft de software de neiging om een dubbele kin te produceren wanneer de kin in het beeld samenvalt met de bovenste rand van het overhemd. Het lukt ook nog niet goed om de emotie waarmee de tekst wordt uitgesproken goed in beeld te brengen: tussen een serieuze speech en wat los gebabbel is geen verschil te zien qua uitdrukking. Het lukt ook nog niet om de tongbeweging goed in beeld te brengen bij het uitspreken van woorden met de Engelse 'th'.
Het algoritme heeft meer beperkingen. Er is bijvoorbeeld veel goed trainingsmateriaal nodig. Dat is bij Obama geen probleem, maar zal bij andere personen vaak minder gemakkelijk te zijn. Los van deze restricties zijn de door de onderzoekers getoonde resultaten verbluffend goed.
Nieuw is het inplakken van spraak in een gezicht overigens niet. Dat gebeurt onder andere met vervormingssoftware die de lipbeweging afstemt op de gesproken tekst. Maar omdat die software het gebied rond de mond niet meeneemt ziet het er erg gekunsteld uit. Er zijn ook geavanceerdere technieken zoals face2face van de Stanford University, maar dat maakt geen gebruik maakt van zo’n lange videotraining en levert mede daardoor een minder overtuigend resultaat.





